Profiler
Profiler zeigen, wo ein Programm CPU-Zeit verbraucht und wie sich Rechenzeit über Funktionen verteilt. Das erlaubt, Hotspots zu identifizieren und Optimierungen gezielt zu steuern. Profiler messen aktive CPU-Ausführung, nicht Wartezeiten oder Blockaden. Wie diese Daten gewonnen werden, hängt von der jeweiligen Profiling-Methode ab.
Sampling-Profiler
Sampling-Profiler arbeiten statistisch. Sie unterbrechen ein laufendes Programm periodisch oder bei Überlauf eines Hardware-Counters und erfassen den aktuellen Ausführungspunkt. Aus vielen Stichproben entsteht ein Profil der CPU-Zeitverteilung mit geringem Overhead und die Laufzeit bleibt meist nahezu unverändert. Daher eignen sich Sampling-Profiler auch für große Programme oder produktionsnahe Last.
Die Methode hat aber Grenzen. Sehr kurze oder selten ausgeführte Funktionen können statistisch unterrepräsentiert sein. Außerdem verschiebt Compiler-Inlining Kosten häufig in aufrufende Funktionen, was die Interpretation erschwert.
Linux perf
Unter Linux ist perf (https://perfwiki.github.io/main/) das zentrale Werkzeug für Sampling-Profiling. Es nutzt Hardware-Performance-Counter moderner CPUs und kann eine Vielzahl von Ereignissen erfassen, etwa CPU-Cycles, ausgeführte Instruktionen oder Cache-Misses.
Neben reinen Hotspot-Listen kann perf auch Aufrufgraphen (engl. Callgraphs) erzeugen. Diese zeigen nicht nur, welche Funktionen teuer sind, sondern auch, über welche Aufrufpfade sie erreicht werden. Das ist entscheidend, um zu erkennen, ob ein Hotspot von vielen Stellen oder nur von einem einzelnen Codepfad gespeist wird.
Die Qualität solcher Callgraphs hängt davon ab, ob der Profiler den aktuellen Aufrufstapel korrekt zurückverfolgen kann, also rekonstruieren kann, welche Funktionen einander aufgerufen haben (dieses Zurückverfolgen nennt man Stack Unwinding). Starke Compiler-Optimierungen oder entfernte Frame-Pointer können diese Rekonstruktion erschweren und zu unvollständigen Callgraphs führen.
Instrumentierungs-Profiler
Instrumentierungs-Profiler verfolgen einen anderen Ansatz. Hier fügt der Compiler Messcode an Funktionsanfang und -ende ein. Dadurch lassen sich Eintritts- und Austrittszeiten exakt bestimmen und Aufrufhäufigkeiten präzise zählen.
Diese Genauigkeit hat ihren Preis. Jeder Funktionsaufruf wird messbar verlangsamt, teils erheblich. Das Messsystem beeinflusst also das Laufzeitverhalten selbst. Dieser Effekt ist als Probe Effect bekannt und kann Ergebnisse verzerren, insbesondere bei sehr häufig aufgerufenen Funktionen oder Rekursion.
gprof
Ein älteres, heute nur noch eingeschränkt genutztes Instrumentierungswerkzeug ist gprof. Es gilt als veraltet, ist aber leicht einzusetzen und deshalb für Lehrzwecke oder kleine Programme weiterhin brauchbar.
Um gprof zu verwenden, wird das Programm mit Instrumentierungs-Code kompiliert. GCC und Clang fügen diesen Messcode über die Option -pg ein. Während der Laufzeit werden Funktionsaufrufe und Laufzeiten erfasst. Nach Programmende schreibt das Programm Profildaten, die anschließend von gprof ausgewertet werden.
Da gprof kein echtes Thread-Bewusstsein besitzt und Laufzeiten nur vergleichsweise grob erfasst, ist seine Aussagekraft begrenzt. Besonders bei modernen, nebenläufigen oder stark optimierten Programmen entstehen dadurch unvollständige oder verzerrte Profile. In solchen Fällen sind Sampling-Profiler meist die bessere Wahl.
Valgrind Callgrind
Callgrind verfolgt einen nochmals tieferen Ansatz. Es führt Programme in einer instrumentierten virtuellen CPU aus. Jede Instruktion und jeder Funktionsaufruf werden dabei gezählt.
Das Ergebnis ist ein extrem detailliertes Kostenmodell. Man sieht, wie viele Instruktionen einzelne Funktionen oder sogar Codezeilen verursachen und wie sich Aufrufbeziehungen zusammensetzen.
Der Nachteil ist die massive Verlangsamung. Laufzeiten verlängern sich oft um den Faktor zehn bis hundert. Callgrind eignet sich daher primär für Offline-Analysen kleinerer Workloads, nicht für Produktionsmessungen.
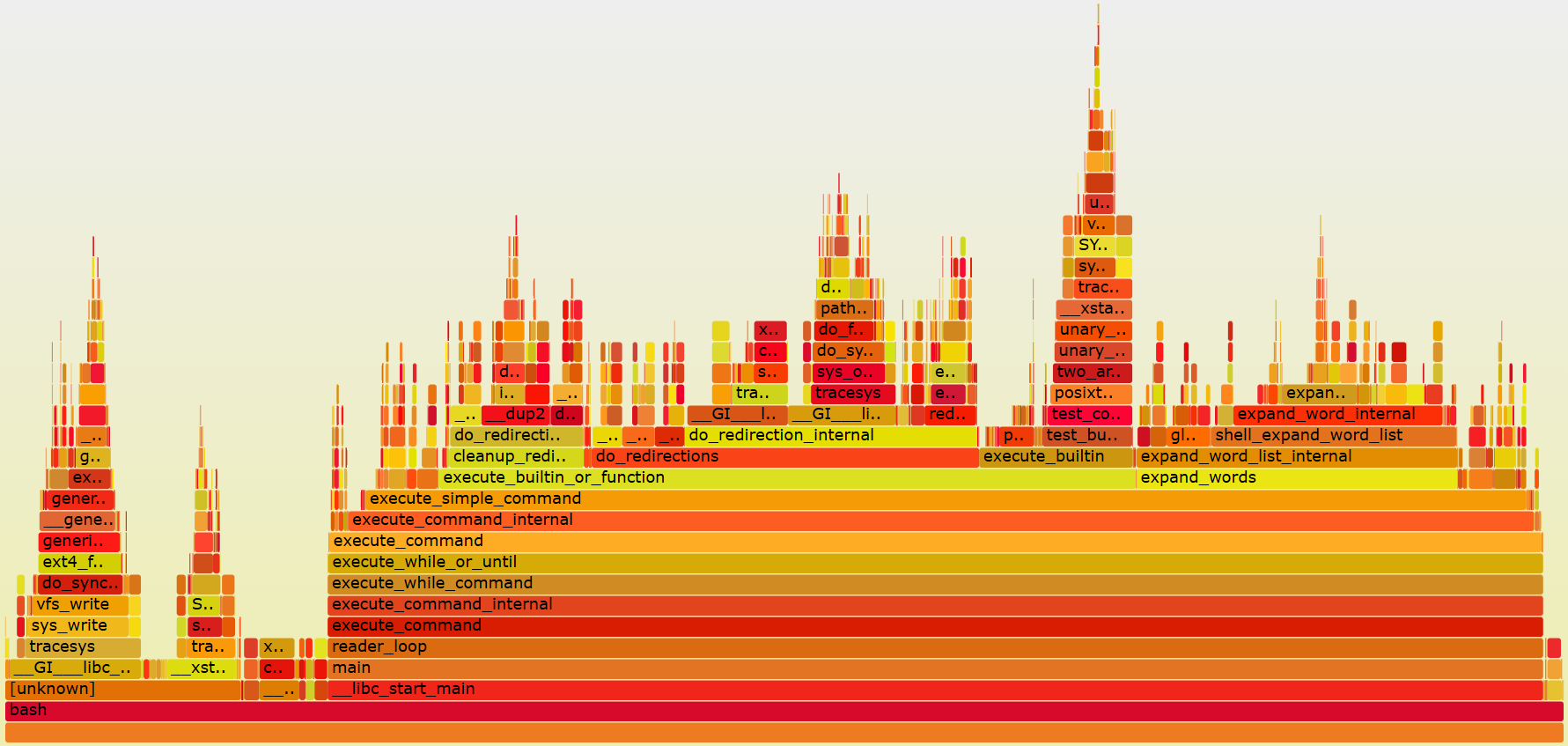
Flame Graphs
Flame Graphs sind keine eigene Messmethode, sondern eine Visualisierungsform für Sampling-Daten. Sie stellen Aufrufstapel als gestapelte Balken dar. Die horizontale Breite eines Balkens entspricht der aggregierten Sample-Häufigkeit. Sie ist also ein Maß für CPU-Zeit, keine Zeitachse. Die vertikale Ausdehnung bildet die Tiefe des Aufrufstapels ab. Breite Strukturen weisen auf Hotspots hin, tiefe Strukturen auf verschachtelte Aufrufketten, etwa Rekursion oder stark geschichtete Bibliotheksaufrufe. Interaktive SVG-Flame-Graphs erlauben das Hineinzoomen bis auf einzelne Funktionen.
Erzeugt werden Flame Graphs typischerweise aus Sampling-Profilern. Unter Linux ist ein gängiger Weg die Kombination aus perf und den Flame-Graph-Skripten von Brendan Gregg (https://github.com/brendangregg/FlameGraph). Dabei werden zunächst Samples aufgezeichnet, anschließend in ein gefaltetes Stack-Format umgewandelt und daraus das SVG generiert.
 Beispiel von der GitHub-Webseite
Beispiel von der GitHub-Webseite
Beispielhaft:
$ perf record -g ./program
$ perf script > out.perf
# Verarbeitung mit FlameGraph-Tools:
$ stackcollapse-perf.pl out.perf > out.folded
$ flamegraph.pl out.folded > flamegraph.svg
Das resultierende SVG lässt sich im Browser öffnen und interaktiv analysieren.
Line-Level-Profiling
Während klassische Profile auf Funktionsebene arbeiten, erlaubt Line-Level-Profiling eine feinere Auflösung. Dabei werden Samples nicht nur Funktionen, sondern einzelnen Codezeilen oder Instruktionen zugeordnet.
Unter Linux ist diese Analyse Teil der perf-Werkzeugsuite. Subkommandos wie perf annotate (und in grafischen Frontends auch Analyseansichten) greifen auf zuvor aufgezeichnete Profildaten zu und zerlegen Funktionen bis auf Assembler- oder Quellzeilenebene. Dadurch kann nachvollzogen werden, welche Instruktionen oder Codeabschnitte innerhalb einer Funktion dominieren. Man erkennt etwa, ob Kosten in Schleifen, Speicherzugriffen oder bestimmten Rechenoperationen entstehen. Das ist vor allem dann relevant, wenn ein Algorithmus selbst nicht austauschbar ist, aber Implementierungsdetails Performance kosten.
Solche Detailanalysen sollten erst erfolgen, nachdem algorithmische und strukturelle Optimierungen ausgeschöpft sind. Mikrooptimierungen ohne klaren Hotspot-Nachweis sind selten zielführend.
Blinde Flecken von Profilern
Profiler zeigen nur aktive CPU-Ausführung. Wenn ein Programm langsam wirkt, obwohl keine Funktion auffällig teuer ist, liegt die Ursache oft außerhalb reiner Rechenzeit.
Typische Fälle sind:
- Dateisystem- oder Netzwerk-I/O
- Sleep-Aufrufe
- Lock-Contention
- Scheduler-Preemption
In solchen Situationen vergeht Zeit, ohne dass CPU-Samples entstehen. Zur Analyse benötigt man Tracing-Werkzeuge.