Von C zu Assembler
Die Übersetzung von Quelltext in ausführbaren Maschinencode ist kein monolithischer Vorgang, sondern eine Abfolge klar abgegrenzter Verarbeitungsschritte. Diese Aupfteilung ist kein Detail moderner Implementierungen, sondern ein grundlegendes Strukturprinzip heutiger Compiler.
In diesem Kapitel schauen wir uns die einzelnen Schritte genauer an, insbesondere welche Optimierungsmöglichkeiten ein moderner C-Compiler hat.
Ablauf der Übersetzung
Ausgangspunkt ist immer die Textdatei mit C-Quellcode. Der C-Standard legt fest, welche Programme gültig sind und welches beobachtbare Verhalten sie haben müssen. Er macht jedoch keine Vorgaben darüber, wie ein Compiler intern aufgebaut sein soll oder in welchen Schritten die Übersetzung erfolgt. Diese Freiheit hat zu einem in der Praxis weitgehend einheitlichen Modell geführt. Dieses Modell beschreibt zunächst nicht einzelne Programme wie Compiler, Assembler oder Linker, sondern die funktionalen Phasen innerhalb eines Compilers.
Von C über IR zu Assembler und Objektdatei
Ein moderner C-Compiler gliedert sich konzeptionell in drei Hauptbereiche: Frontend, Optimierer und Backend.
Im Frontend analysiert der Compiler den Quelltext zunächst lexikalisch. Der Zeichenstrom wird in Token zerlegt, etwa Schlüsselwörter, Bezeichner, Literale und Operatoren.
Darauf folgt die syntaktische Analyse, die überprüft, ob diese Token eine grammatikalisch korrekte Struktur bilden. Ergebnis dieser Phase ist eine baumartige interne Darstellung des Programms, der abstrakte Syntaxbaum (Abstract Syntax Tree, AST). Er bildet die syntaktische Struktur des Programms ab, noch weitgehend unabhängig von späteren Optimierungen oder der Zielarchitektur.
Der AST wird anschließend in eine Intermediate Representation (IR) überführt. Diese Zwischendarstellung ist kein C-Code mehr und auch noch kein Assembler. Sie ist expliziter als die Quellsprache, streng typisiert und so aufgebaut, dass alle relevanten Seiteneffekte sichtbar sind. Genau diese Eigenschaften machen sie geeignet für automatische Analysen und Transformationen. GCC verwendet hierfür mehrere IR-Stufen, unter anderem GIMPLE und später RTL. Clang setzt auf LLVM IR. Diese Repräsentationen unterscheiden sich in Details und Ausdrucksform, folgen aber denselben Grundideen: Abstraktion von der Quellsprache, weitgehende Unabhängigkeit von der Zielarchitektur und gute Eignung für Optimierungen.
Die Optimierungsphase arbeitet fast vollständig auf dieser IR-Ebene. Hier entscheidet sich, welche Teile des ursprünglichen Programms im späteren Maschinencode überhaupt noch sichtbar sind. Überflüssige Variablen können entfernt werden, konstante Ausdrücke zusammengefasst, gemeinsam genutzte Teilausdrücke wiederverwendet oder Berechnungen aus Schleifen herausgezogen werden. Auch ganze Codepfade können entfallen, wenn ihr Effekt auf das beobachtbare Programmverhalten nachweislich null ist. Diese Optimierungen sind überwiegend architekturunabhängig und verändern nicht die Semantik des Programms, wohl aber dessen Struktur.
Erst im Backend erfolgt die Abbildung der optimierten IR auf eine konkrete Zielarchitektur wie x86-64, ARM oder RISC-V. In diesem Schritt werden abstrakte Operationen in konkrete Maschineninstruktionen übersetzt. Dabei berücksichtigt der Compiler die verfügbaren Register, Instruktionsformate, Adressierungsarten und die geltenden Aufrufkonventionen. Das Backend erzeugt entweder textuellen Assemblercode (wie bei GCC) oder direkt binären Maschinencode in einer Objektdatei (wie bei Clang/LLVM). In beiden Fällen spiegelt das Ergebnis die Architekturdetails explizit wider.
Zusammengefasst: Das Frontend ist für die Analyse der Quellsprache zuständig, der Optimierer arbeitet auf einer sprachunabhängigen Zwischendarstellung, und das Backend erzeugt Code für eine konkrete Zielarchitektur. Diese Phasen beschreiben die interne Arbeitsweise eines Compilers, unabhängig davon, welche konkreten Werkzeuge später beteiligt sind.
Die mehrstufige Aufteilung erlaubt eine klare Trennung von Verantwortlichkeiten. Frontend, Optimierer und Backend können unabhängig entwickelt und verbessert werden. Außerdem kann dieselbe IR als Basis für viele Zielarchitekturen dienen. Ein Frontend kann dabei unterschiedliche Programmiersprachen wie C, C++ oder Rust verarbeiten, während ein Backend denselben optimierten IR-Code in Maschinencode für verschiedene Zielarchitekturen übersetzt, etwa für unterschiedliche Prozessorfamilien, Instruktionssätze oder Maschinenmodelle. Das ist der zentrale Grund, warum Compiler wie GCC oder Clang auf einer Vielzahl sehr unterschiedlicher Plattformen verfügbar sind.
Rolle von Compiler, Assembler und Linker
Die internen Phasen der Übersetzung wurden bereits beschrieben. Nun geht es um die beteiligten Programme: Compiler, Assembler und Linker. Sie erfüllen unterschiedliche Aufgaben, die im Übersetzungsprozess aufeinander aufbauen.
Der Compiler (genauer: sein Backend) erzeugt entweder textuellen Assemblercode oder direkt eine Objektdatei mit binärem Maschinencode.
Dieser Assemblercode wird anschließend vom Assembler in eine Objektdatei übersetzt. Die Objektdatei enthält binären Maschinencode, ist aber noch nicht vollständig bestimmt. Zusätzlich zum Code enthält sie Symboltabellen, Relokationsinformationen und optional Debugging-Daten. Adressen sind an dieser Stelle oft noch relativ oder unvollständig, da Referenzen auf externen Code noch nicht aufgelöst sind. Der Assembler arbeitet auf einer wesentlich niedrigeren Ebene. Er kennt keine Typen, keine Blöcke und keine Kontrollstrukturen. Seine Aufgabe ist es, symbolische Instruktionen in Binärcode zu übersetzen, Offsets zu berechnen und Sprungziele aufzulösen, soweit dies lokal möglich ist. Der Assembler interpretiert den Code nicht semantisch. Er setzt lediglich eine formale Beschreibung in eine binäre Darstellung um.
Der Linker verbindet schließlich eine oder mehrere Objektdateien zu einem ausführbaren Programm oder einer Bibliothek. Er löst externe Symbole auf, ordnet Code- und Datensegmente im virtuellen Adressraum an und erzeugt das endgültige Binärformat, etwa ELF oder PE. Erst in diesem Schritt stehen die finalen Adressen von Funktionen und globalen Daten fest.
Warum Assembler anschauen?
Wir haben gesehen, welche Rolle Compiler, Assembler und Linker spielen und wie sie zusammenarbeiten. Assembler ist die erste Darstellung, in der die Abstraktionen von C weitgehend verschwunden sind. Konzepte wie Variablen, Ausdrücke oder Kontrollstrukturen existieren dort nicht mehr. Stattdessen sieht man Register, Speicheradressen, Lade- und Speicheroperationen, Vergleiche und Sprünge. Der erzeugte Assemblercode selbst kam dabei bisher noch nicht vor. Das ändern wir in diesem Kapitel. Wir schauen uns gezielt die Assembler-Ausgabe an, die der Compiler produziert, denn damit lässt sich nachvollziehen, was der Compiler tatsächlich aus unserem C-Code macht.
Durch den Blick auf den erzeugten Code sehen wir konkret:
- Wohin kommen Variablen: Register oder Speicher?
- Wie werden Ausdrücke berechnet?
- Wie werden Fallunterscheidungen, Schleifen oder Funktionen umgesetzt?
- Welche Optimierungen finden statt und warum verschwindet manchmal Code oder verschwinden Variablen?
Das schärft das Verständnis für Themen wie Variablenlebensdauer, Speicherlayout, Alignment, Registerdruck oder Inlining. Allerdings wollen wir weder Assembler selbst schreiben noch jede Instruktion verstehen. Assembler ist für uns lediglich ein Beobachtungswerkzeug, um zu sehen, was der Compiler aus dem C-Code gemacht hat. Dieses Kapitel wird nicht jede Instruktion erklären oder jedes Register einordnen; dafür ist das Thema zu speziell und an vielen Stellen zu technisch. Entscheidend ist nur, ein grundsätzliches Gefühl dafür zu bekommen, wie ein C-Programm auf Maschinenebene abgebildet wird.
Für die Abbildung von C auf Assembler nutzen wir den Compiler Explorer (https://godbolt.org, kurz „Godbolt“). Dort lässt sich C-Code im Browser kompilieren und die Assembler-Ausgabe direkt neben dem Quellcode anzeigen -- ohne Installation oder komplizierte Compileroptionen. Änderungen am Code sind sofort sichtbar.
Mit diesem Ziel vor Augen schauen wir uns nun an, wie Variablen, Speicher und Register auf Maschinenebene zusammenhängen.
Variablen, Speicher und Register
C und Assembler beschreiben dasselbe Programm, jedoch auf unterschiedlichen Abstraktionsebenen. C stellt uns ein Modell mit benannten Variablen, Typen, Speicherbereichen sowie Regeln für Sichtbarkeit und Lebensdauer zur Verfügung. Assembler beschreibt Programme dagegen unmittelbar in Begriffen der Zielhardware. Dort existieren nur Register, Speicheradressen und Instruktionen.
Konzepte, die in C voneinander getrennt sind, werden auf der Maschinenebene auf eine deutlich reduzierte Menge physischer Mittel abgebildet. Der Compiler übernimmt die Aufgabe, diese Abbildung so vorzunehmen, dass die semantischen Regeln von C eingehalten werden.
C-Speicherbereiche aus Sicht der Sprache
Der C-Standard unterscheidet mehrere Klassen von Objekten, die sich in Lebensdauer, Sichtbarkeit und Initialisierung unterscheiden. Diese Unterscheidung ist semantischer Natur und beschreibt nicht, wo oder wie die Objekte physisch gespeichert werden. Fassen wir das noch einmal zusammen:
Automatische Variablen werden innerhalb von Funktionen deklariert. Ihre Lebensdauer beginnt beim Betreten des umgebenden Blocks und endet beim Verlassen dieses Blocks. Bei jedem Funktionsaufruf entstehen neue Instanzen dieser Variablen.
void function() {
int local = 42;
}
Statische Variablen besitzen Programmlaufzeit. Sie werden genau einmal initialisiert und behalten ihren Wert über Funktionsaufrufe hinweg, auch wenn sie innerhalb einer Funktion deklariert sind.
void counter() {
static int count = 0;
count++;
}
Globale Variablen besitzen ebenfalls Programmlaufzeit und sind grundsätzlich im gesamten Programm sichtbar, sofern ihre Sichtbarkeit nicht eingeschränkt wird.
int global_state = 100;
Das Schlüsselwort static bei globalen Variablen beschränkt ihre Sichtbarkeit auf die aktuelle Translation Unit (also typischerweise eine .c-Datei plus inkludierte Header). Ihr Lebensdauerverhalten entspricht dem globaler Variablen, ihre Sichtbarkeit ist jedoch eingeschränkt.
static int file_private = 0;
Dynamisch allokierter Speicher wird zur Laufzeit über Funktionen wie malloc() angefordert und mit free() wieder freigegeben. Die Lebensdauer dieses Speichers wird explizit vom Programm gesteuert.
int *dynamic = malloc(sizeof(int));
free(dynamic);
Der C-Standard beschreibt diese Kategorien ausschließlich über ihre semantischen Eigenschaften. Aussagen über konkrete Speicherorte oder physische Umsetzung werden nicht getroffen.
Physische Speicherorte der Zielhardware
Auf der Maschinenebene existieren nur zwei grundlegende Speicherorte: Register und Hauptspeicher.
Register sind kleine, schnelle Speicherzellen im Prozessor. Rechenoperationen arbeiten allgemein auf Registerinhalten. Werte müssen daher vor der Verarbeitung in Register geladen werden. Die Anzahl verfügbarer Register ist begrenzt, was den Compiler zu sorgfältiger Planung zwingt.
Der Hauptspeicher bietet einen großen Adressraum, ist jedoch deutlich langsamer als Register. Der Zugriff erfolgt über Speicheradressen. Daten im Hauptspeicher können nicht direkt verarbeitet werden, sondern müssen zunächst in Register geladen werden.
Aus Sicht der Hardware gibt es keine getrennten Speicherarten für lokale, globale oder statische Variablen. Alle diese Konzepte werden auf Register und Hauptspeicher abgebildet.
Hinweis: Die Anzahl der Register ist architekturabhängig und begrenzt. x86-64-Prozessoren stellen 16 allgemeine 64-Bit-Ganzzahlregister zur Verfügung, von denen einige feste oder konventionelle Rollen haben (z. B. Stack-Pointer). Zusätzlich existieren spezialisierte Register für Gleitkomma- und Vektoroperationen, etwa 16 XMM-Register (für SSE), die als YMM-Register (AVX) oder ZMM-Register (AVX-512) erweitert werden können. ARM64 (AArch64) definiert 31 allgemeine Register (X0–X30), wobei einzelne Register konventionell besondere Aufgaben übernehmen, etwa X30 als Link-Register für Funktionsrücksprünge. RISC-V definiert 32 Register, wobei X0 fest auf null verdrahtet ist und somit 31 nutzbare Register zur Verfügung stehen.
Da die Anzahl der Register begrenzt ist, konkurrieren viele Werte um wenige Registerplätze. Die Entscheidung, welcher Wert zu welchem Zeitpunkt in welchem Register liegt, wird als Registerallokation bezeichnet und ist eine der zentralen Aufgaben des Compilers. Reichen die Register nicht aus oder wird die Adresse eines Werts benötigt, muss der Compiler auf den Hauptspeicher ausweichen.
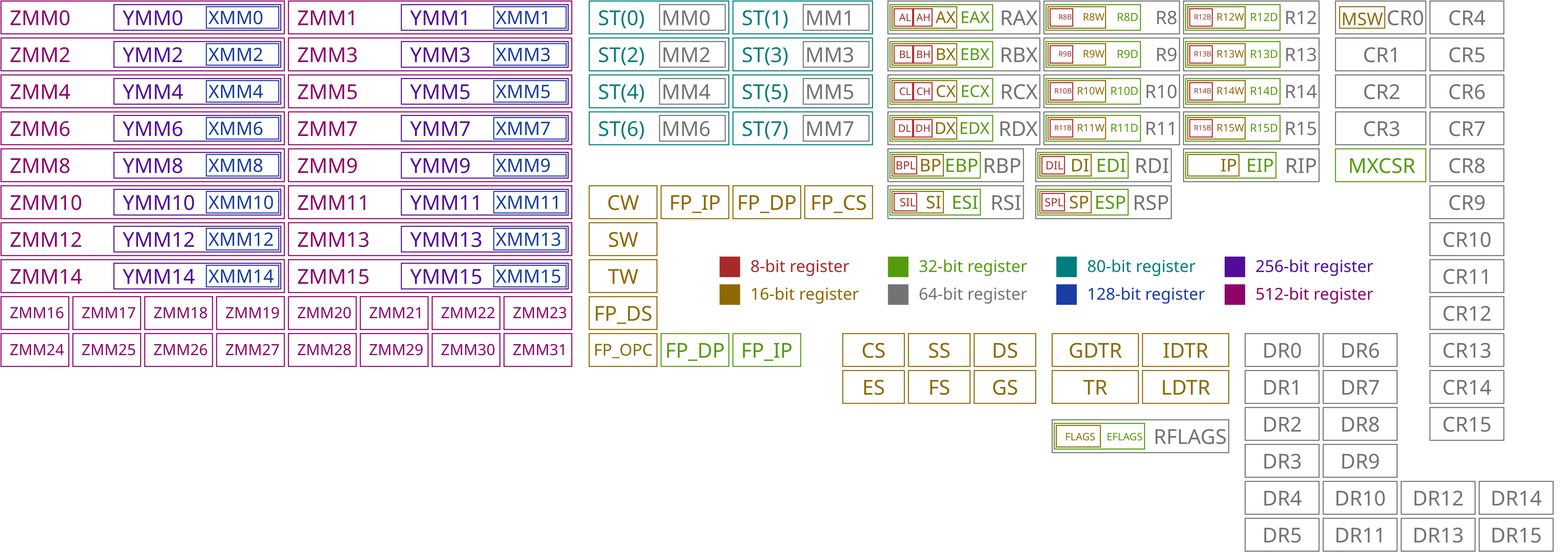
Im x86-64-Befehlssatz verfügbare Register (Quelle: https://en.wikipedia.org/wiki/X86#x86_registers)
C-Objekte und ihre Speicherregionen
C kennt unterschiedliche Objektklassen mit klar definierter Lebensdauer. Der Compiler bildet diese semantischen Konzepte auf konkrete Speicherbereiche und Register ab. Die genaue Umsetzung ist nicht festgelegt, sondern Ergebnis von Analyse und Optimierung.
Globale Variablen und statische Variablen besitzen statische Lebensdauer. Sie existieren über die gesamte Programmlaufzeit und erhalten einen festen Speicherplatz im Programmimage. (Ein Programmimage ist die vollständige binäre Darstellung eines Programms, so wie sie vom Compiler und Linker erzeugt wird und vor der Ausführung vorliegt.) Die Adresse wird zur Link-Zeit festgelegt. Globale und statische Variablen liegen in Datensegmenten:
.data: Enthält initialisierte globale und statische Variablen. Die Initialwerte sind Teil der ausführbaren Datei und werden beim Programmstart in den Speicher geladen.
.bss: Enthält uninitialisierte globale und statische Variablen. Das Segment belegt keinen Platz für Daten im Programmimage, sondern nur für Größenangaben. Beim Programmstart werden die zugehörigen Speicherbereiche mit Null initialisiert. BSS steht für "Block Started by Symbol".
Automatische Variablen auf der anderen Seite entstehen bei jedem Funktionsaufruf neu. Sie haben eine begrenzte Lebensdauer und werden typischerweise im Hauptspeicher auf dem Stack abgelegt. Jeder Funktionsaufruf reserviert dafür einen Stack-Frame. Dieses enthält lokale Variablen, Rücksprunginformationen und temporäre Daten. Dadurch können mehrere Instanzen derselben Variablen gleichzeitig existieren, etwa bei Rekursion oder verschachtelten Aufrufen.
Die zuvor beschriebenen Speicherentscheidungen -- statische oder automatische Speicherzuordnung -- schlagen sich direkt in der Art der Adressierung nieder:
Datensegmente: Globale und statische Variablen werden über symbolische Adressen angesprochen. Der Linker weist jedem Objekt eine feste Adresse zu. Der erzeugte Code greift direkt über diese Adresse zu, nicht über den Stack.
Stack: Automatische Variablen liegen an festen Offsets relativ zum aktuellen Stack-Frame. Diese Offsets sind zur Compile-Zeit bekannt, die absolute Adresse ergibt sich erst zur Laufzeit. Der Compiler verwendet dafür üblicherweise zwei Register:
rspzeigt auf die aktuelle Stackspitzerbpdient häufig als stabiler Bezugspunkt innerhalb des Stack-Frames
Beispiel: Globale und statische Variablen im Assemblercode
Schauen wir uns das an einem konkreten Beispiel an:
// global, initialisiert → .data
int g_init = 123;
// global, nicht initialisiert → .bss
int g_zero;
// ebenfalls .data, aber nur in dieser Translation Unit sichtbar
static int file_private = 7;
int main() {
static int s_init = 5; // .data (Programmlaufzeit),
// trotz Deklaration in der Funktion
static int s_zero; // .bss
s_init += g_init;
g_zero = s_init + s_zero;
}
Typischer Assemblerauszug (x86-64, Intel-Syntax, GCC, sinngemäß gekürzt):
.data # initialisierte Daten (.data)
.align 4 # 4-Byte Alignment für int
"s_init.1":
.long 5 # static int s_init = 5; (Initialwert in Datei)
.bss # nicht initialisierte Daten (.bss)
.align 4 # 4-Byte Alignment für int
"g_zero":
.zero 4 # int g_zero; (nur Platz, Loader setzt auf 0)
.data # zurück zu .data
.align 4
"g_init":
.long 123 # int g_init = 123; (Initialwert steht in Datei)
.text # Code-Sektion
.globl "main" # Symbol main ist global sichtbar
"main":
# eax = g_init (global, liegt im Datensegment)
mov eax, DWORD PTR "g_init"[rip]
# eax += s_init (static, liegt ebenfalls im Datensegment)
add eax, DWORD PTR "s_init.1"[rip]
# s_init = eax (writeback ins Datensegment)
mov DWORD PTR "s_init.1"[rip], eax
# g_zero = eax (global, .bss, write ins Datensegment)
mov DWORD PTR "g_zero"[rip], eax
mov eax, 0 # Rückgabewert main = 0
ret # Rücksprung
Wichtig ist hier nur das Muster:
- Zugriffe auf globale oder statische Daten erfolgen über einen symbolischen Namen wie
g_init[rip]oders_init.1[rip], also über benannte Speicheradressen im Datensegment. - Ob eine Variable in
.dataoder.bssliegt, sieht man an den Direktiven:.long <Wert>(Initialwert vorhanden) versus.zero <Größe>(nur Platz, Startwert 0).
Intel- oder AT&T-Syntax: Der gezeigte Code verwendet die Intel-Syntax. Dabei gilt: Zieloperand links, Quelloperand rechts (
mov eax, DWORD PTR g_init[rip]). Register erscheinen ohne%, und Speicherzugriffe tragen explizite Größenangaben wieDWORD PTR.GCC und Clang können Assembler sowohl in Intel- als auch in AT&T-Syntax ausgeben. Die AT&T-Syntax ist bei GCC traditionell der Standard; dort ist die Operandenreihenfolge umgekehrt, Register sind mit
%markiert, und Größen werden über Instruktionssuffixe angegeben (z. B.movl).
In diesem Beispiel erfolgen alle Speicherzugriffe über symbolische Adressen wie g_init[rip] oder s_init.1[rip] und beziehen sich auf globale oder statische Daten. Zugriffe relativ zu rbp oder rsp treten hier nicht auf. (Diese Register dienen der Stack-Verwaltung: rsp zeigt auf die aktuelle Stackspitze, rbp wird häufig als fester Bezugspunkt für lokale Variablen innerhalb eines Stack-Frames verwendet.) Solche Zugriffe erscheinen erst bei lokalen automatischen Variablen im nächsten Beispiel.
Load/Store-Prinzip
Register sind die einzigen Speicherorte, auf denen der Prozessor direkt rechnen kann. Selbst einfache Operationen wie Addition oder Vergleich arbeiten auf Registerinhalten. Werte im Hauptspeicher müssen daher vor der Verarbeitung in Register geladen und Ergebnisse anschließend wieder gespeichert werden.
Viele moderne Prozessorarchitekturen folgen dem Load/Store-Prinzip, bei dem Rechenoperationen strikt von Speicherzugriffen getrennt sind. Speicherzugriffe dienen ausschließlich dem Laden (load) von Werten in Register und dem Speichern (store) von Ergebnissen aus Registern in den Hauptspeicher. Diese Trennung prägt den Aufbau von Assemblercode und zwingt den Compiler dazu, zu entscheiden, welche Werte wann in Registern gehalten werden.
Beispiel: Lokale Variablen und Stack-Zugriffe
Betrachten wir folgendes einfaches C-Programm mit mehreren lokalen Variablen:
int main() {
int base = 10;
int factor = 3;
int offset = 5;
int temp = base * factor;
int result = temp + offset;
return result;
}
Für jede Rechenstufe folgt der Prozessor demselben Grundmuster: Benötigte Werte werden aus dem Speicher in Register geladen, die Operation wird auf Registerinhalten ausgeführt, und das Ergebnis wird anschließend wieder im Speicher abgelegt. In Pseudosyntax könnte das so aussehen:
load base -> R1
load factor -> R2
mul R1, R2 -> R3
store R3 -> temp
load temp -> R4
load offset -> R5
add R4, R5 -> R6
store R6 -> result
Im echten x86-Assembler ist das Load/Store-Prinzip ebenfalls vorhanden, aber für Ungeübte nicht gut lesbar:
"main":
push rbp #
mov rbp, rsp #,
# int base = 10;
mov DWORD PTR [rbp-4], 10 # base,
# int factor = 3;
mov DWORD PTR [rbp-8], 3 # factor,
# int offset = 5;
mov DWORD PTR [rbp-12], 5 # offset,
# int temp = base * factor;
mov eax, DWORD PTR [rbp-4] # tmp101, base
imul eax, DWORD PTR [rbp-8] # temp_4, factor
mov DWORD PTR [rbp-16], eax # temp, temp_4
# int result = temp + offset;
mov edx, DWORD PTR [rbp-16] # tmp106, temp
mov eax, DWORD PTR [rbp-12] # tmp107, offset
add eax, edx # result_5, tmp106
mov DWORD PTR [rbp-20], eax # result, result_5
# return result;
mov eax, DWORD PTR [rbp-20] # _6, result
# }
pop rbp #
ret
Im Assemblercode tauchen verschiedene Register auf: rbp (Base-Pointer) und rsp (Stack-Pointer) dienen der Stack-Verwaltung. Außerdem sind eax und edx 32-Bit-Versionen der Allzweckregister rax und rdx. Zu Beginn des Beispiels bauen die Befehle (push rbp, mov rbp, rsp) den Stack-Frame auf, am Ende lösen (pop rbp, ret) ihn wieder auf. Mit der Notation DWORD PTR [rbp-4] wird auf einen 32-Bit-Wert (DWORD = Double Word = 4 Bytes) an der Speicheradresse zugegriffen, die 4 Bytes unterhalb von rbp liegt. Am Zeilenende stehen Kommentare (z.B. # base), die der Compiler ergänzt hat und die zeigen, welche C-Variable an dieser Stelle gemeint ist.
Auswirkungen von Optimierungen auf den erzeugten Code
Bis zu diesem Punkt zeigt das Beispiel ausschließlich das mechanische Load/Store-Verhalten eines nicht optimierten Übersetzungsvorgangs. Jede C-Variable wird einem festen Speicherplatz im Stack-Frame zugeordnet, Rechenoperationen erfolgen dennoch ausschließlich in Registern.
Erst mit aktivierten Optimierungen ändert sich diese Abbildung grundlegend. Moderne Compiler analysieren den Lebensbereich und die Verwendung lokaler Variablen und versuchen, sie vollständig in Registern zu halten. Der Stack wird nur dann verwendet, wenn Register nicht ausreichen oder wenn eine Variable eine Adresse im Hauptspeicher besitzen muss.
Wird die Adresse einer lokalen Variable gebildet, etwa durch den Adressoperator (&), ist eine Ablage im Hauptspeicher zwingend erforderlich. Ein Register besitzt keine stabile Speicheradresse im Sinne des C-Sprachmodells.
In optimiertem Code (Compiler-Option -O1, Optimierungsstufe 1) kann derselbe C-Code mit der main-Funktion aus dem Beispiel auf wenige Instruktionen reduziert werden:
"main":
mov eax, 35
ret
In diesem Fall existiert keine der C-Variablen mehr als eigenständige Speicherzelle. Der Compiler rechnet das Ergebnis einfach selbstständig aus und liefert das Ergebnis 35 zurück.
Abhängig von Analyse und Optimierung kann eine Variable:
- ausschließlich als Registerwert existieren,
- vollständig zur Compile-Zeit berechnet werden,
- entfallen, wenn ihr Wert nie verwendet wird,
- oder sich einen Speicherort oder ein Register mit anderen Variablen teilen.
Variablen aus dem C-Quelltext sind damit keine festen Speicherobjekte, sondern abstrakte Größen, deren physische Repräsentation vom Compiler bestimmt wird.
Konsequenzen für das Lesen von Assemblercode
Beim Lesen von generiertem Assemblercode ist es meist sinnlos, nach den originalen Variablennamen zu suchen. Stattdessen sollte der Datenfluss zwischen Registern und Speicher verfolgt werden.
Register werden mehrfach wiederverwendet und repräsentieren zu unterschiedlichen Zeitpunkten unterschiedliche Werte. Stack-Zugriffe deuten häufig auf nicht optimierten Code oder auf Variablen hin, deren Adresse benötigt wird.
Das Verständnis dieser Abbildung zwischen C-Abstraktion und Maschinenebene ist Voraussetzung für effektives Debugging, die Analyse von Compiler-Optimierungen und die Interpretation von generiertem Assemblercode.
Typische C-Konstrukte und ihr Assemblerpendant
Auf Assemblerebene existieren keine abstrakten Kontrollstrukturen. Konstrukte wie if, else, switch oder Schleifen werden vollständig auf Vergleiche, Statusflags, bedingte Sprünge und Sprungmarken (Labels) reduziert. Der Compiler übersetzt die logische Struktur des C-Codes in linearen Kontrollfluss mit expliziten Sprungzielen.
if/else und Vergleiche
Typischerweise läuft Eine fallunterscheidung in drei Schritten ab: Zuerst werden die Operanden in Register geholt, dann wird ein Vergleich ausgeführt, der Statusflags setzt, und anschließend entscheidet ein bedingter Sprung anhand dieser Flags, welcher Zweig ausgeführt wird. Ein Ausdruck, wie x < y, existiert danach nicht mehr als „Ausdruck“, sondern nur noch als „Sprungentscheidung“.
#include <stdio.h>
int x = 10;
int y = 20;
int main() {
if (x < y) {
puts("x ist kleiner"); // 📣 x ist kleiner
} else {
puts("x ist nicht kleiner");
}
}
Der erzeugte Assemblercode (-O1) sieht so aus:
.LC0:
.string "x ist kleiner"
.LC1:
.string "x ist nicht kleiner"
"main":
sub rsp, 8 # Stack-Alignment für Funktionsaufrufe
mov eax, DWORD PTR "y"[rip] # eax = y
cmp DWORD PTR "x"[rip], eax # Vergleich setzt Flags anhand von x-y
jge .L2 # wenn x >= y → else-Zweig
mov edi, OFFSET FLAT:.LC0 # Argument für puts: "x ist kleiner"
call "puts" # puts("x ist kleiner")
jmp .L3 # danach else-Zweig überspringen
.L2:
mov edi, OFFSET FLAT:.LC1 # Argument für puts: "x ist nicht ..."
call "puts" # puts("x ist nicht kleiner")
.L3:
mov eax, 0 # Rückgabewert von main
add rsp, 8
ret
"y":
.long 20
"x":
.long 10
Der zentrale Punkt ist hier der Vergleich mit cmp. Auf x86 ist cmp a, b keine „Vergleichsfunktion“, sondern intern eine Subtraktion, die nur die Statusflags setzt. In diesem Beispiel entspricht cmp DWORD PTR "x"[rip], eax der Rechnung x - y. Das Ergebnis wird nicht gespeichert, aber die CPU setzt Flags wie Zero Flag (Ergebnis war 0), Sign Flag (Ergebnis negativ) und Overflow Flag (Überlauf bei signed Interpretation). Genau diese Flags sind die Grundlage für den nachfolgenden bedingten Sprung.
Der Sprung jge .L2 bedeutet „springe, wenn größer oder gleich“ im Sinne eines signed Vergleichs. Da die Flags vom Ausdruck x - y kommen, ist jge genau dann wahr, wenn x - y >= 0 ist, also wenn x >= y gilt. Und das ist genau der Fall, in dem die Bedingung x < y nicht erfüllt ist. Deshalb verzweigt der Code bei erfülltem jge direkt zum Label .L2, also in den else Zweig. Eine Sprungmarke (engl. Label) ist ein symbolischer Name für eine konkrete Codeadresse. Erst der Assembler löst diese Labels auf und ersetzt sie durch feste Zieladressen, sodass die CPU beim Ausführen nur noch mit absoluten oder relativen Sprungzielen arbeitet.
Wenn die Bedingung x < y hingegen wahr ist, wird jge nicht genommen und der Code läuft linear weiter in den if-Zweig. Nach dem puts im if-Zweig folgt dann ein unbedingter Sprung jmp .L3, damit der else Teil nicht ebenfalls ausgeführt wird. .L3 ist dabei das gemeinsame Ende der Fallunterscheidung, an dem beide Pfade wieder zusammenlaufen.
Dass der Assemblercode auf x >= y testet, obwohl im C-Code x < y steht, ist kein Widerspruch, sondern ein typisches Muster. Der Compiler formuliert die Bedingung oft so, dass der „Fehlerfall“ oder „Nicht erfüllt“ Fall per Sprung behandelt wird, während der andere Pfad direkt im linearen Fluss liegt. Dadurch wird der Code meist einfacher zu strukturieren, und je nach Layout kann das auch der Sprungvorhersage der CPU entgegenkommen.
Sobald logische Operatoren wie && und || dazukommen, wird diese Sprunglogik meist verschachtelt. Der Compiler setzt dann Kurzschluss-Auswertung um: Bei && reicht ein falscher Teilausdruck, um direkt in den „false“ Pfad zu springen, und bei || reicht ein wahrer Teilausdruck, um den Rest zu überspringen. Das führt nicht zu „magischen“ Maschinenbefehlen, sondern schlicht zu mehr Vergleichen, mehr Labels und mehr bedingten Sprüngen, die die gleiche Idee weiterführen.
Ein switch-Statement ist für den Compiler eine besondere Form von Mehrfachverzweigung. Wie diese Verzweigung im Assembler umgesetzt wird, hängt stark davon ab, wie viele case-Labels es gibt und wie die zugehörigen Werte verteilt sind.
Sind nur wenige Fälle vorhanden oder liegen die
case-Werte weit auseinander, entscheidet sich der Compiler meist für eine lineare Umsetzung. Er erzeugt dann eine Abfolge von Vergleichen mit anschließendem bedingtem Sprung, die funktional mehreren hintereinander geschaltetenif-Anweisungen entspricht. Jeder Vergleich prüft, ob derswitch-Ausdruck einem bestimmtencase-Wert entspricht, und verzweigt bei Erfolg direkt in den zugehörigen Codeblock. Trifft kein Vergleich zu, läuft der Kontrollfluss am Ende in dendefault-Zweig oder hinter dasswitch-Statement.Anders sieht es aus, wenn viele
case-Labels existieren und deren Werte dicht beieinanderliegen, etwa bei einem Bereich wie0bis20. In diesem Fall wäre eine lange Kette von Vergleichen ineffizient. Der Compiler kann stattdessen eine Sprungtabelle (engl. jump table) erzeugen. Diese Sprungtabelle ist ein Array von Codeadressen, wobei jede Position einem möglichencase-Wert entspricht. Derswitch-Ausdruck wird zunächst auf einen Index normiert, meist durch Subtraktion des kleinstencase-Werts, und anschließend als Index in dieser Tabelle verwendet. Über einen indirekten Sprung wird dann direkt zur passenden Zieladresse verzweigt. Aus Sicht des Prozessors bedeutet das, dass der Kontrollfluss nicht mehr über mehrere bedingte Sprünge läuft, sondern über genau einen indirekten Sprung. Das kann deutlich schneller sein, insbesondere bei vielen Fällen. Damit die Tabelle nicht zu groß wird, muss der Compiler fallweise entscheiden, welche Strategie sinnvoll ist, und kann für denselbenswitch-Code je nach Optimierungsstufe oder Zielarchitektur unterschiedliche Assemblerstrukturen erzeugen.
Schleifen
Auch while-, do-while- und for-Schleifen existieren auf Assemblerebene nicht als eigene Konstrukte. Genau wie if und else werden sie vollständig über Sprünge realisiert. Grundsätzlich unterscheidet man zwei Arten von Sprüngen. Ein unbedingter Sprung wie jmp wird immer ausgeführt und verändert den Kontrollfluss ohne weitere Prüfung. Ein bedingter Sprung wie je, jne, jl oder jge hängt dagegen vom Zustand der Statusflags ab, die zuvor durch einen Vergleich oder eine arithmetische Operation gesetzt wurden. Schleifen entstehen aus der Kombination dieser beiden Elemente: einem Vergleich, der entscheidet, ob die Schleife fortgesetzt wird, und einem Sprung, der entweder zurück an den Anfang oder aus der Schleife herausführt.
Schauen wir uns die Umsetzung einer while-Schleife an:
#include <stdio.h>
int main() {
int i = 0;
while (i < 3) {
printf("%d\n", i); // 📣 0 // 📣 1 // 📣 2
i++;
}
}
Der dazugehörige Assemblercode kann etwa so aussehen:
.LC0:
.string "%d\n"
"main":
push rbx # rbx wird benutzt und daher gesichert
mov ebx, 0 # i = 0
.L2: # Beginn der Schleife
mov esi, ebx # zweites Argument für printf: i
mov edi, OFFSET FLAT:.LC0 # erstes Argument: Formatstring
mov eax, 0 # laut ABI für variadische Funktionen nötig
call "printf" # printf("%d\n", i)
add ebx, 1 # i++
cmp ebx, 3 # Vergleich: i - 3
jne .L2 # solange i != 3 → zurück zum Schleifenanfang
mov eax, 0 # Rückgabewert von main
pop rbx # rbx wiederherstellen
ret
Das Label .L2 markiert den Einstiegspunkt der Schleife. Es gibt keinen separaten „Schleifenkopf“ im abstrakten Sinn, sondern nur diese eine Adresse, zu der der Code immer wieder zurückspringt. Nach dem Schleifenkörper wird i inkrementiert und anschließend mit 3 verglichen. Der Vergleich cmp ebx, 3 setzt die Statusflags anhand von i - 3. Der folgende Sprung jne .L2 bewirkt, dass der Code so lange zum Label .L2 zurückspringt, wie i ungleich 3 ist. Sobald i den Wert 3 erreicht, wird der Sprung nicht mehr ausgeführt, und der Kontrollfluss läuft aus der Schleife heraus.
Die Bedingung i < 3 aus dem C-Code erscheint nicht direkt. Stattdessen prüft der Assemblercode, ob i != 3. Diese Umformulierung ist typisch. Der Compiler wählt eine Bedingung, die sich mit einem einzelnen Vergleich und einem einfachen bedingten Sprung ausdrücken lässt. Für diese konkrete Schleife ist i != 3 äquivalent zu i < 3, da i bei 0 beginnt und nur inkrementiert wird.
Je nach Optimierungsstufe und Struktur des Codes kann der Compiler Schleifen auch anders anordnen. Eine while-Schleife kann in eine Form übersetzt werden, bei der die Bedingung am Ende steht, wie in diesem Beispiel, oder am Anfang geprüft wird. Ebenso kann eine for-Schleife intern wie eine while-Schleife aussehen oder in eine do-while-ähnliche Struktur überführt werden. Für den Assembler ist das unerheblich: Entscheidend sind nur Vergleiche, Sprünge und Labels, aus denen sich der zyklische Kontrollfluss zusammensetzt.
Funktionen
Auf Assemblerebene sind Funktionen nichts anderes als Codebereiche mit einem festen Einstiegspunkt und einem definierten Rücksprung. Alles, was in C wie ein abstrakter Funktionsaufruf wirkt, wird auf Maschinenebene auf eine genau festgelegte Abfolge von Speicher- und Sprungoperationen reduziert. Dazu gehören das Bereitstellen der Argumente, das Springen in den Funktionscode, die Rückgabe eines Ergebnisses und die Verwaltung des Stacks. Damit all diese Schritte zwischen unabhängig kompilierten Codeabschnitten zuverlässig zusammenpassen, folgen sie einer festen Konvention, der sogenannten Aufrufkonvention (engl. Calling Convention).
Funktionsaufruf und Aufrufkonvention
Ein Funktionsaufruf lässt sich gedanklich in mehrere Phasen zerlegen.
. Zunächst bereitet die aufrufende Funktion, der Aufrufer (engl. Caller), die Argumente vor. . Anschließend springt der Aufrufer in die aufgerufene Funktion, den Aufgerufenen (engl. Callee). . Dieser führt den Code aus, legt einen Rückgabewert fest und kehrt schließlich wieder zum Aufrufer zurück.
Die Aufrufkonvention legt dabei fest, in welchen Registern oder an welchen Stackpositionen Argumente zu liegen haben, wo das Rückgabeergebnis zu finden ist und welche Register von welcher Seite erhalten werden müssen. Unter x86-64 Linux gilt die System V AMD64 ABI. (Quelle: System V Application Binary Interface AMD64 Architecture Processor Supplement, § 3.2 Function Calling Sequence). Sie definiert unter anderem:
- dass die ersten sechs ganzzahligen oder zeigerartigen Argumente in den Registern
rdi,rsi,rdx,rcx,r8undr9übergeben werden - dass Gleitkommaargumente getrennt davon in den SSE-Registern
xmm0bisxmm7übergeben werden - dass weitere Argumente, sofern die vorgesehenen Register nicht ausreichen, vom Aufrufer auf dem Stack abgelegt werden
- dass der Rückgabewert einer Funktion bei ganzzahligen Typen im Register
raxund bei Gleitkommatypen im Registerxmm0bereitgestellt wird
Unter Windows x86-64 wird die Microsoft x64 Calling Convention verwendet. Auch hier ist alles strikt festgelegt, aber die Details unterscheiden sich deutlich von Linux. Daraus ergeben sich andere Registerbelegungen und andere Pflichten für Caller und Callee. Kurz gesagt: Unter Linux sind mehr Argumentregister verfügbar, dafür gibt es keinen verpflichtenden Shadow Space. Unter Windows sind es weniger Argumentregister, dafür ist der Stackaufbau stärker standardisiert. Wir gehen im Folgenden von der System-V-ABI aus.
Beispiel und Umsetzung
Das folgende Beispiel kombiniert ganzzahlige und Gleitkommaargumente in einer Funktion:
#include <stdio.h>
double sum(int a, int b, int c, double d) {
return a + b + c + d;
}
int main() {
return (int)sum(1, 2, 3, 4);
}
Der dazugehörige Assemblercode (-O1) könnte so aussehen. (Durch die Optimierung erzeugt der Compiler bewusst kompakten Code und verzichtet auf einen expliziten Stackframe, da er für die Berechnung nicht erforderlich ist.)
"sum":
movapd xmm1, xmm0 # d aus xmm0 sichern (später noch benötigt)
add edi, esi # edi = a + b
add edi, edx # edi = a + b + c
pxor xmm0, xmm0 # xmm0 auf 0.0 setzen
cvtsi2sd xmm0, edi # Ganzzahlergebnis → double
addsd xmm0, xmm1 # + d
ret # Rückgabe in xmm0
Beim Eintritt in die Funktion sum befinden sich die Argumente bereits vollständig gemäß der Aufrufkonvention in den vorgesehenen Registern. Die Ganzzahlargumente a, b und c liegen in edi, esi und edx, während das Gleitkommaargument d in xmm0 übergeben wird. Die drei Ganzzahlargumente werden addiert, das Ergebnis in einen Gleitkommawert umgewandelt und schließlich mit dem vierten Argument d addiert. Das Endergebnis befindet sich am Ende wieder in xmm0, genau dort, wo die Aufrufkonvention es für einen double-Rückgabewert verlangt.
Der Aufruf aus main sieht so aus (Code nicht optimiert):
"main":
push rbp
mov rbp, rsp
mov rax, QWORD PTR .LC0[rip] # Bitmuster von 4.0 laden
movq xmm0, rax # d = 4.0
mov edx, 3 # c = 3
mov esi, 2 # b = 2
mov edi, 1 # a = 1
call "sum" # Funktionsaufruf
cvttsd2si eax, xmm0 # Rückgabewert double → int
pop rbp
ret
.LC0:
.long 0
.long 1074790400 # 4.0 als double
Hier wird gut sichtbar, wie der Aufrufer die Argumente exakt nach Konvention vorbereitet. Die Ganzzahlen landen in edi, esi und edx, der Gleitkommawert wird in xmm0 geladen. Der call-Befehl erledigt zwei Dinge gleichzeitig: Er legt die Rücksprungadresse, also die Adresse des nächsten Befehls nach call, auf dem Stack ab und setzt den Instruction-Pointer auf den Einstiegspunkt von sum. Der ret-Befehl in sum nimmt diese Adresse wieder vom Stack und springt genau dorthin zurück. Auf diese Weise sind auch verschachtelte Funktionsaufrufe möglich, da jede Funktion ihre eigene Rücksprungadresse verwaltet.
Register mit und ohne Bestandsschutz Ein weiterer wichtiger Aspekt der Aufrufkonvention ist die Einteilung der Register in Caller-Saved- und Callee-Saved-Register. Register wie
rax,rcx,rdx,rsi,rdiundr8bisr11darf eine aufgerufene Funktion frei verändern. Wenn der Aufrufer deren Inhalte nach dem Aufruf noch benötigt, muss er sie vorher selbst sichern. Demgegenüber stehen Callee-Saved-Register wierbx,rbpundr12bisr15. Verändert eine Funktion eines dieser Register, ist sie verpflichtet, den ursprünglichen Wert vor dem Rücksprung wiederherzustellen. Compiler, Debugger und Exception-Handling bauen genau auf diesen Aufrufkonvention auf. Daher ist auch Assemblercode, der unter Linux korrekt ist, nicht automatisch unter Windows korrekt, selbst auf derselben Architektur. Die Aufrufkonvention ist Teil der ABI und damit Teil der Plattform, nicht der CPU.
Zeigerzugriffe
Zeiger speichern Adressen von Objekten und ermöglichen damit einen indirekten Zugriff auf Daten. Was in C als „Zeiger“ erscheint, ist auf Assemblerebene nur eine Zahl, die als Speicheradresse interpretiert wird. Diese Adresse kann in einem Register liegen oder im Speicher abgelegt sein. Ein Zeigerzugriff wird daher immer auf einfache Speicheroperationen zurückgeführt, nämlich auf Instruktionen, die Daten von einer berechneten Adresse laden oder an eine berechnete Adresse schreiben.
Die entscheidende Frage ist dabei nicht, dass ein Zugriff indirekt ist, sondern wie die Zieladresse berechnet wird. Genau hier setzt die Adressberechnung an.
Adressberechnung
Ein Zeigerzugriff in C lässt sich gedanklich in zwei Schritte zerlegen. Zuerst wird die Adresse bestimmt, auf die der Zeiger verweist. Erst danach erfolgt der eigentliche Zugriff auf die Daten an dieser Adresse. Die Adressberechnung kann sehr einfach sein, etwa bei einer direkten Dereferenzierung wie *p, oder komplexer werden, wenn Indizes, Offsets oder Arrayzugriffe ins Spiel kommen.
Moderne Prozessoren unterstützen solche Berechnungen direkt in der Speicheradressierung. Auf x86 kann eine effektive Adresse aus bis zu drei Bestandteilen zusammengesetzt werden: einer Basisadresse, einem Indexregister mit Skalierungsfaktor und einem konstanten Offset. Formal lässt sich das als base + index * scale + offset beschreiben. Dieser Mechanismus ist besonders für Arrayzugriffe ausgelegt, da sich Indizes und Elementgrößen direkt abbilden lassen.
Das folgende Beispiel zeigt einen einfachen Arrayzugriff:
#include <stdio.h>
int arr[] = {1, 2, 3};
int main() {
int i = 2;
return arr[i];
}
Der Assemblercode dazu sieht so aus:
"arr":
.long 1
.long 2
.long 3
"main":
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], 2 # i = 2
mov eax, DWORD PTR [rbp-4] # eax = i
cdqe # eax → rax (Vorzeichen erweitern)
mov eax, DWORD PTR "arr"[rax*4] # eax = arr[i]
pop rbp
ret
Der eigentliche Arrayzugriff geschieht in der letzten mov-Instruktion. Hier nutzt der Prozessor einen skalierten Index: rax enthält den Index i, und der Skalierungsfaktor 4 entspricht der Größe eines int in Bytes. Die Basisadresse ist das Symbol arr, also der Anfang des Arrays. Zusammengesetzt ergibt sich damit die Adresse &arr[0] + i * sizeof(int).
Auffällig ist, dass in diesem Beispiel kein expliziter Offset und kein separates Basisregister verwendet werden. Die Basisadresse ist direkt das Symbol arr, der Index kommt aus rax, und die Skalierung übernimmt die Multiplikation mit der Elementgröße. Andere Varianten, etwa Zugriffe auf lokale Arrays oder Strukturelemente, nutzen zusätzlich Offsets relativ zu rbp oder rsp, das Grundprinzip bleibt aber identisch.
Optimierungen können diese Adressberechnung weiter vereinfachen. Ist der Index zur Compilezeit bekannt, kann der Compiler die Zieladresse direkt berechnen und den Zugriff auf eine konstante Adresse reduzieren. Wird ein Zeiger in einer Schleife schrittweise erhöht, kann der Compiler den Code so umformen, dass die Adressaddition nur einmal pro Iteration erfolgt, statt jedes Mal neu berechnet zu werden.
Arrays und Zeiger
Auf Maschinenebene bleibt von Arrays wenig übrig, denn ein Arrayzugriff wie str1[i] ist in C bereits als Zeigerarithmetik definiert, nämlich als *(str1 + i). Sobald der Compiler optimiert, reduziert er beide Schreibweisen auf dasselbe Grundmuster: eine Basisadresse, einen (impliziten oder expliziten) Index und einen Byte-Ladevorgang mit anschließendem Vergleich. Damit ist im fertigen Assembler häufig kaum noch erkennbar, ob der ursprüngliche Quelltext mit Indizes oder mit Zeigerinkrementen geschrieben wurde.
Das folgende Beispiel zeigt zwei Varianten derselben Funktion. Beide vergleichen zwei C-Strings Zeichen für Zeichen. Die erste Version arbeitet explizit mit Zeigern und Post-Inkrementen, die zweite verwendet einen Index und Array-Notation. Trotzdem unterscheidet sich der Assembler-Code und folgt der gewählten Schreibweise über Zeiger oder Arrays.
bool strings_are_equal(const char *str1, const char *str2) {
while (*str1 && *str1++ == *str2++)
;
return *str1 == *str2;
}
Der Assemblercode (-O2 mit Clang):
strings_are_equal:
.LBB0_1:
movzx eax, byte ptr [rdi] # aktuelles Zeichen von *str1 laden
test al, al # auf '\0' prüfen
je .LBB0_2 # Ende von str1 erreicht
inc rdi # str1++
lea rcx, [rsi + 1] # temporär: str2 + 1
cmp al, byte ptr [rsi] # *str1 == *str2 ?
mov rsi, rcx # str2++
je .LBB0_1 # bei Gleichheit nächste Iteration
movzx eax, byte ptr [rdi] # Zeichen nach dem Abbruch laden
mov rsi, rcx
jmp .LBB0_5
.LBB0_2:
xor eax, eax # al = 0 (Nullbyte)
.LBB0_5:
cmp al, byte ptr [rsi] # Vergleich der Abbruchzeichen
sete al # Ergebnis: gleich oder nicht
ret
Die Post-Inkremente aus dem C-Code werden direkt in Registeroperationen umgesetzt. rdi und rsi enthalten die aktuellen Zeigerpositionen. Nach jedem Vergleich werden die Zeiger weitergeschoben, sodass sie immer auf das nächste Zeichen zeigen. Der Kontrollfluss folgt exakt der Logik der while-Bedingung.
Nun die Array-Variante:
#include <stdbool.h>
bool strings_are_equal(const char str1[], const char str2[]) {
int i = 0;
while (str1[i] && str1[i] == str2[i])
i++;
return str1[i] == str2[i];
}
Der Assemblercode sieht wie folgt aus:
strings_are_equal:
movzx ecx, byte ptr [rdi] # str1[0] laden
xor eax, eax # i = 0
test cl, cl # auf '\0' prüfen
je .LBB0_4 # leerer String
.LBB0_1:
cmp cl, byte ptr [rsi + rax] # str1[i] == str2[i] ?
jne .LBB0_5 # Abbruch bei Ungleichheit
movzx ecx, byte ptr [rdi + rax + 1] # nächstes Zeichen str1[i+1]
inc rax # i++
test cl, cl # wieder auf '\0' prüfen
jne .LBB0_1 # nächste Iteration
.LBB0_4:
xor ecx, ecx # cl = 0
.LBB0_5:
cmp cl, byte ptr [rsi + rax] # abschließender Vergleich
sete al # Ergebnis zurückgeben
ret
Hier übernimmt rax die Rolle des Index i. Die Adressierung erfolgt über Ausdrücke wie [rdi + rax] oder [rsi + rax], also genau die formale Umsetzung von str[i]. Statt die Basisadresse zu verschieben, bleibt sie konstant, und der Index wird erhöht. Funktional ist das identisch zur Zeigervariante.
Der entscheidende Punkt ist: Beide Fassungen reduzieren sich auf dasselbe Maschinenmodell. In beiden Fällen berechnet die CPU eine Adresse, lädt ein Byte, vergleicht es und entscheidet über einen Sprung. Ob diese Adresse durch Inkrementieren eines Zeigers oder durch Addieren eines Indexes entsteht, ist eine Frage der Codeform, nicht der Semantik. Deshalb ist im optimierten Assemblercode meist kaum noch zu erkennen, ob der ursprüngliche C-Code mit Arrays oder mit Zeigern formuliert war.
Als Randbemerkung: Mit GCC sieht das Bild oft etwas anders aus. Dort ist die Zeigervariante in vielen Fällen noch kompakter umgesetzt und kommt mit weniger Instruktionen aus. Das liegt nicht an einem grundsätzlichen Unterschied zwischen Arrays und Zeigern, sondern an unterschiedlichen Optimierungsstrategien der Compiler.
Strukturzugriffe
Auf Assemblerebene verlieren Strukturen jede abstrakte Bedeutung. Eine Struktur ist nichts weiter als ein Speicherbereich, dessen einzelne Mitglieder an festen Offsets liegen. Ein Zugriff auf ein Mitglied reduziert sich deshalb immer auf einen normalen Speicherzugriff, bei dem zur Basisadresse der Struktur ein konstanter Offset addiert wird.
Der Compiler legt die Mitglieder einer Struktur grundsätzlich in der Reihenfolge ab, in der sie im C-Code deklariert sind. Dabei kann er jedoch zusätzliches Padding einfügen, um Alignment-Anforderungen der Zielarchitektur einzuhalten. Jedes Mitglied erhält dadurch einen festen, zur Compilezeit bekannten Offset relativ zum Anfang der Struktur. Diese Offsets sind rein statisch und ändern sich zur Laufzeit nicht.
Wird auf eine Struktur über einen Zeiger zugegriffen, unterscheidet sich das Prinzip nicht. Der Zeiger enthält die Basisadresse der Struktur. Beim Zugriff auf ein Mitglied addiert der Compiler den passenden Offset zu dieser Basisadresse und erzeugt daraus einen ganz normalen Lade- oder Speicherbefehl.
Beispiel mit Mitgliederzugriff
Ein Beispiel:
struct Point {
int x, y;
};
struct Point p = {10, 20};
int main() {
struct Point *ptr = &p;
return ptr->x + ptr->y;
}
Der dazugehörige Assemblercode sieht so aus:
"p":
.long 10 # p.x
.long 20 # p.y
"main":
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-8], OFFSET FLAT:"p" # ptr = &p
mov rax, QWORD PTR [rbp-8] # rax = ptr
mov edx, DWORD PTR [rax] # edx = ptr->x (Offset 0)
mov rax, QWORD PTR [rbp-8] # rax erneut = ptr
mov eax, DWORD PTR [rax+4] # eax = ptr->y (Offset 4)
add eax, edx # eax = ptr->x + ptr->y
pop rbp
ret
Zunächst wird die globale Struktur p im Datensegment abgelegt. Das erste Feld x liegt bei Offset 0, das zweite Feld y direkt dahinter bei Offset 4, da ein int auf dieser Plattform vier Byte groß ist. Im Funktionscode wird der Zeiger ptr als einfache Adresse behandelt und auf dem Stack gespeichert. Anschließend wird diese Adresse in ein Register geladen, um die eigentlichen Feldzugriffe durchzuführen. Der Zugriff auf ptr\->x reduziert sich auf einen Lesezugriff von der Adresse, auf die rax zeigt. Da x das erste Mitglied der Struktur ist, wird kein zusätzlicher Offset benötigt. Der Zugriff auf ptr\->y erfolgt analog, allerdings mit einem konstanten Offset von vier Byte. Der Compiler erzeugt dafür einen Speicherzugriff mit Adressberechnung, hier rax + 4.
Arrays innerhalb von Strukturen werden nach demselben Schema behandelt. Die Elemente des Arrays liegen direkt hintereinander im Speicher und sind Teil der Struktur. Die Gesamtgröße der Struktur erhöht sich um die Größe des Arrays, und die Offsets aller nachfolgenden Mitglieder verschieben sich entsprechend. Für den Compiler macht es keinen Unterschied, ob ein Offset zu einem einzelnen Mitglied oder zu einem bestimmten Arrayelement gehört.
Verschachtelte Strukturen werden ebenfalls vollständig inline abgelegt. Eine innere Struktur belegt einen zusammenhängenden Bereich innerhalb der äußeren Struktur. Die Offsets der Mitglieder der inneren Struktur ergeben sich aus der Summe des Offsets der inneren Struktur innerhalb der äußeren Struktur und des Offsets des jeweiligen Mitglieds innerhalb der inneren Struktur. Auch hier handelt es sich ausschließlich um zur Compilezeit berechnete Konstanten, die sich im Assemblercode direkt als feste Zahlen wiederfinden.
Optimierungen bei kleinen Strukturen
Bei ausreichend kleinen Strukturen kann der Compiler Optimierungen vornehmen und die Struktur ganz oder teilweise in Registern halten. Ein struct Point mit zwei int-Mitgliedern passt beispielsweise exakt in ein 64-Bit-Register. In solchen Fällen kann eine Struktur als Ganzes über Register übergeben oder zurückgegeben werden, ohne dass Speicherzugriffe nötig sind.
struct Point {
int x, y;
};
struct Point make_point() {
struct Point p = {0x01234567, 0x89ABCDEF};
return p;
}
Der Assemblercode für diese Funktion kann dann so aussehen:
"make_point":
movabs rax, 0x89ABCDEF01234567 # y | x in einem 64-Bit-Register
ret
Hier wird die gesamte Struktur in rax zurückgegeben. Die unteren 32 Bit enthalten das Mitglied x, die oberen 32 Bit das Mitglied y. Der Aufrufer weiß aufgrund der Calling Convention und des bekannten Strukturtyps, wie diese Bits zu interpretieren sind, und kann die Mitglieder entsprechend extrahieren.
Diese Form der Rückgabe funktioniert nur für kleine Strukturen, die in Register passen und von der ABI dafür zugelassen sind. Größere Strukturen werden anders behandelt. Entweder legt der Aufrufer Speicher für das Ergebnis an und übergibt einen Zeiger darauf, oder die Struktur wird über den Stack transportiert. Welche Variante verwendet wird, ist ebenfalls durch die Calling Convention festgelegt.
Ein häufiger Fehler ist die Annahme, dass Strukturen immer dicht gepackt sind und dass sich Offsets einfach aus der Summe der Mitgliedergrößen ergeben. Durch Alignment und Padding kann die tatsächliche Größe einer Struktur deutlich größer sein als erwartet. Deshalb sollte man sich im Zweifel nicht auf Annahmen verlassen, sondern sizeof verwenden und das tatsächliche Layout im erzeugten Assemblercode überprüfen, wenn genaue Kenntnisse über die Speicheranordnung erforderlich sind.
Eigenen Assemblercode einbetten
Manchmal reicht der vom Compiler erzeugte Code nicht aus. In bestimmten Situationen stößt C an strukturelle Grenzen:
Auf Mikrocontrollern existieren häufig Spezialinstruktionen ohne direkte Entsprechung in C. Dazu zählen das Setzen von Statusregistern, der Zugriff auf Coprozessoren oder spezielle atomare Operationen. Solche Funktionen lassen sich oft nur zuverlässig über Assembler abbilden.
Auch auf modernen CPUs ist Assembler relevant. SIMD-Instruktionen (Single Instruction, Multiple Data) erlauben die parallele Verarbeitung mehrerer Datenwerte. Aktuelle Architekturen stellen dafür umfangreiche Befehlssätze bereit, etwa SSE und AVX auf x86 oder NEON auf ARM. Compiler erzeugen SIMD-Code teilweise automatisch, doch für maximale Kontrolle und reproduzierbare Performance werden kritische Schleifen häufig manuell implementiert.
Um diese Grenzen zu umgehen, kann Assemblercode entweder direkt in ein C-Programm eingebettet oder in Form separater Assemblerprogramme mit C-Code kombiniert und im Link-Vorgang verbunden werden. Beide Ansätze ermöglichen den gezielten Einsatz einzelner Maschineninstruktionen dort, wo C nicht genügend Kontrolle bietet oder wo sehr hohe Performance-Anforderungen bestehen.
C selbst bietet für diese Anforderungen keine standardisierte Lösung. Der C-Standard definiert keine Syntax zum Einbetten von Assemblercode und überlässt dieses Thema vollständig den Compilerherstellern. In der Praxis haben sich daher herstellerspezifische Erweiterungen etabliert, mit denen sich Assemblerinstruktionen direkt in C-Code integrieren lassen. Diese Erweiterungen sind nicht portabel und stets an einen konkreten Compiler gebunden.
Inline-Assembler nutzen
Compilererweiterungen erlauben es, Assemblercode direkt in C-Code einzubetten. Dabei werden einzelne Maschinenbefehle aus C heraus ausgeführt, ohne auf externe Assemblerdateien auszuweichen. Der Compiler integriert diese Instruktionen unmittelbar in den erzeugten Maschinencode und berücksichtigt sie bei Registervergabe und Optimierung.
Die drei verbreitetsten Compiler haben eine andere Syntax:
GCC und Clang verwenden dieselbe Syntax für erweiterten Inline-Assembler. Clang implementiert diese Syntax als kompatible Schnittstelle zu GCC. (Unterschiede ergeben sich nicht in der Schreibweise, sondern in der Interpretation einzelner Constraints, in der Fehlerdiagnose und in der Interaktion mit Optimierungen.) So nutzen beide Compiler das Schlüsselwort
asmoder__asm__, gefolgt von einem Inline-Assembler-Block in einer speziellen Syntax, die als "extended asm"MSVC verwendet eine einfachere Syntax ohne die erweiterten Möglichkeiten von GCC. Außerdem ist die Assemblereinbettung nur auf 32-Bit-x86 verfügbar. In 64-Bit-Targets unterstützt MSVC keinen Inline-Assembler; dort sind externe Assemblerdateien oder Compilerintrinsics erforderlich. Microsoft begründet das unter anderem mit der komplexeren Register- und Calling-Convention auf x64, die eine sichere Integration von Inline-Assembler erschwert.
Registerzuweisung, Inputs, Outputs, Clobbers
Die Assembler-Syntax von GCC und Clang trennt den eigentlichen Assemblercode von der Schnittstelle zur C-Welt. Diese Trennung erfolgt über drei Abschnitte, getrennt durch Doppelpunkte:
__asm__ volatile (
"Assemblercode"
: Outputs
: Inputs
: Clobbers
);
volatile verhindert, dass der Compiler den Assemblerblock wegoptimiert. Ohne volatile könnte der Compiler den Code entfernen, wenn er keine beobachtbaren Effekte auf C-Variablen feststellt.
Outputs definieren, welche C-Variablen der Assemblercode beschreibt. Das Format ist "Constraint" (Variable). Die häufigsten Constraints sind "=r" (beliebiges Register, Write) und "=m" (Speicheradresse, Write). Ein kleines Beispiel:
#include <stdio.h>
int main() {
int result;
__asm__ ("movl $42, %0" : "=r" (result));
printf("Wert: %d\n", result); // 📣 Wert: 42
}
Ein weiteres Beispiel: Das Lesen eines Hardware-Zeitstempels auf x86. Die rdtsc-Instruktion (Read Time-Stamp Counter) liest einen CPU-internen Zähler:
#include <stdio.h>
#include <stdint.h>
#include <inttypes.h>
static inline uint64_t read_tsc() {
uint32_t low, high;
__asm__ volatile ("rdtsc" : "=a" (low), "=d" (high));
return ((uint64_t)high << 32) | low;
}
int main() {
uint64_t start = read_tsc();
// Irgendeine Berechnung
volatile int x = 0;
for (int i = 0; i < 1000000; i++) x += i;
uint64_t end = read_tsc();
printf("Zyklen: %" PRIu64 "\n", end - start);
// 📣 Zyklen: <architekturabhängig>
}
Die rdtsc-Instruktion schreibt das Ergebnis in zwei Register: %eax (untere 32 Bit) und %edx (obere 32 Bit). Die Constraints "=a" und "=d" weisen den Compiler an, diese Register den Variablen low und high zuzuordnen. Solche Funktionen kommen in Treibern, Betriebssystem-Kernel und Embedded-Software häufig vor. (Quelle: Der Linux-Kernel verwendet Inline-Assembler dort, wo C-Compiler-Builtins oder standardisierte Sprachmittel für Kontextwechsel, atomare Speicherzugriffe und Speicherbarrieren nicht ausreichen oder keine korrekte architekturspezifische Semantik liefern. Unter https://github.com/torvalds/linux/tree/master/arch/x86/include/asm finden sich zahlreiche Header-Dateien, die solche Low-Level-Funktionen als Inline-Assembler implementieren.)
Inputs beschreiben C-Variablen, die vom Assemblercode gelesen werden. Das = entfällt, da kein Schreibzugriff erfolgt:
#include <stdio.h>
int main() {
int a = 10, b = 20, sum;
__asm__ ("addl %2, %1\n\t"
"movl %1, %0"
: "=r" (sum)
: "r" (a), "r" (b));
printf("Summe: %d\n", sum); // 📣 Summe: 30
}
Die Platzhalter %0, %1, %2 beziehen sich auf die Reihenfolge der Operanden. Zuerst werden alle Outputs gezählt, danach die Inputs. Die konkrete Registerwahl trifft der Compiler.
Clobbers geben an, welche Register oder Ressourcen der Assemblercode verändert, ohne dass sie als Outputs deklariert sind. Typische Einträge sind Registernamen oder das Schlüsselwort "memory":
int x = 100;
__asm__ volatile (
"movl $50, %%eax"
:
:
: "%eax", "memory"
);
In der Clobber-Liste selbst steht nur ein einfaches Prozentzeichen ("%eax"). Der Clobber "memory" teilt dem Compiler mit, dass Speicherinhalte beliebig verändert werden können. Dadurch werden Speicherzugriffe vor und nach dem Assemblerblock nicht umgeordnet. Ohne diesen Hinweis könnte der Optimizer fälschlicherweise annehmen, dass Speicherwerte unverändert bleiben.
Ein Beispiel aus der ARM-Cortex-M-Welt: das Deaktivieren von Interrupts. Die Instruktion cpsid i (Change Processor State, Interrupt Disable) schaltet alle Interrupts ab. In C gibt es dafür keine standardisierte Funktion, aber über Assembler lässt sich das lösen:
static inline void disable_interrupts() {
__asm__ volatile ("cpsid i" ::: "memory");
}
Der "memory"-Clobber verhindert, dass der Compiler Speicherzugriffe über diese Funktion hinweg umordnet. Das ist entscheidend, weil Interrupt-Sperren oft kritische Abschnitte schützen.
Die Wahl der richtigen Constraints und Clobbers ist wichtig. Der Compiler verlässt sich vollständig auf diese Informationen. Fehler führen zu subtilen und schwer reproduzierbaren Bugs, insbesondere bei höheren Optimierungsstufen oder auf anderen Architekturen.
Externe Assemblerdateien
Inline-Assembler ist nicht immer geeignet. Größere Assemblerblöcke machen C-Code schwer lesbar und schlecht wartbar. Außerdem unterstützt MSVC Inline-Assembler nur auf 32-Bit-x86. In solchen Fällen wird der Assemblercode in separate Dateien ausgelagert. Diese Dateien werden zu Objektdateien assembliert und im Link-Schritt mit den C-Objektdateien verbunden. Aus Sicht von C erscheinen diese Routinen als normale externe Funktionen, beschrieben durch Funktionsprototypen, die die jeweilige Schnittstelle festlegen.
Ganze Assemblerprogramme schreiben
GCC und Clang verwenden typischerweise .s für Assembler-Quelldateien. (Dateien mit der Endung .S werden zusätzlich durch den C-Präprozessor verarbeitet.) NASM und ähnliche Assembler nutzen meist .asm. Der Inhalt besteht aus Assemblercode, ohne C-Syntax. Abhängig vom Tool können jedoch Präprozessor-Direktiven erlaubt sein.
Ein einfaches Beispiel: Eine Funktion, die zwei Ganzzahlen addiert und das Ergebnis zurückgibt. Die Datei add.s für x86-64 mit GAS-Syntax (GNU Assembler):
.text
.globl add_numbers
.type add_numbers, @function
add_numbers:
movl %edi, %eax
addl %esi, %eax
ret
Die .globl-Direktive macht das Symbol add_numbers für den Linker sichtbar. Die .type-Direktive kennzeichnet es als Funktion. Die Instruktionen selbst sind normaler x86-Assembler: Der erste Parameter wird in %edi übergeben, der zweite in %esi. Der Rückgabewert steht in %eax.
Für NASM müsste dieselbe Funktion explizit als global deklariert werden, zum Beispiel mit global add_numbers, da sonst kein extern sichtbares Symbol erzeugt wird.
Auf ARM (AArch64) sieht derselbe Code anders aus. Ein minimales Beispiel in GAS-Syntax:
.text
.globl add_numbers
.type add_numbers, %function
add_numbers:
add w0, w0, w1
ret
Hier liegen die Parameter in w0 und w1. Das Ergebnis verbleibt in w0. Die Calling Convention unterscheidet sich grundlegend von x86-64, sowohl in der Registerbelegung als auch im Umgang mit dem Stack.
Der Assemblercode wird separat übersetzt:
$ as -o add.o add.s # GNU Assembler (GAS)
# oder
$ nasm -f elf64 add.asm # NASM
Aufruf aus C über Prototypen
#include <stdio.h>
// Prototyp der externen Assemblerfunktion
int add_numbers(int a, int b);
int main() {
int result = add_numbers(15, 27);
printf("Ergebnis: %d\n", result);
}
Der Linker verbindet den C-Code mit dem Assemblercode:
$ cc -c main.c -o main.o
$ cc -o program main.o add.o
Der entscheidende Punkt: Der C-Compiler kennt die Implementierung von add_numbers nicht. Er verlässt sich darauf, dass die Funktion die deklarierte Signatur einhält und die gültige Calling Convention korrekt umsetzt. Fehler im Assemblercode, etwa falsche Registerverwendung, beschädigte Stack-Daten oder eine inkorrekte Parameteranzahl, führen zu undefiniertem Verhalten, das der Compiler nicht erkennen kann.
Portabilität und Vorsicht
Assemblercode ist das Gegenteil von portabel. Der offensichtlichste Unterschied ist der Befehlssatz. Die Registeranzahl variiert ebenfalls. Mehr Register bedeuten oft effizienteren Code, weil weniger Werte auf den Stack ausgelagert werden müssen.
Die Endianness unterscheidet sich manchmal. x86 ist Little-Endian, ARM kann beide Modi unterstützen (meist Little-Endian), MIPS kann beide. Code, der Bytes direkt manipuliert, muss diese Unterschiede berücksichtigen.
Die Ausrichtungsanforderungen variieren. ARM erlaubt je nach Architektur unaligned Zugriffe nur eingeschränkt. Auf älteren ARM-Varianten können Zugriffe auf nicht ausgerichtete Adressen zu einem Fehler führen. Auch auf AArch64 sind unaligned Zugriffe nicht immer kostenfrei oder für alle Instruktionen erlaubt. x86 erlaubt unaligned Zugriffe, aber sie sind langsamer. SIMD-Instruktionen erfordern meist eine Ausrichtung auf 16 oder 32 Bytes.
Im vorangehenden Kapitel haben wir schon über die Aufrufkonvention gesprochen; sie definiert, wie Parameter übergeben werden, wo Rückgabewerte stehen und welche Register über Funktionsaufrufe hinweg erhalten bleiben müssen. Die Aufrufkonvention ist architekturabhängig und teilweise auch betriebssystemspezifisch. Ohne ihre korrekte Einhaltung ist eine saubere Zusammenarbeit zwischen C und Assembler nicht möglich.
Auf x86-64 unter Linux gilt die System V AMD64 ABI. Die ersten sechs Integer-Parameter werden in
%rdi,%rsi,%rdx,%rcx,%r8und%r9übergeben. Weitere Parameter liegen auf dem Stack. Der Rückgabewert wird in%raxgeliefert. Die Register%rbx,%rbpund%r12bis%r15sind callee-saved und müssen von der aufgerufenen Funktion erhalten bleiben. Alle anderen Register gelten als caller-saved.Auf ARM (AArch64) werden die ersten acht Parameter in
x0bisx7übergeben, bei 32-Bit-Werten inw0bisw7. Der Rückgabewert steht inx0. Die Registerx19bisx28sind callee-saved, währendx0bisx18vom Caller als zerstörbar betrachtet werden müssen.Windows x64 verwendet eine andere Konvention. Die ersten vier Parameter werden in
%rcx,%rdx,%r8und%r9übergeben. Zusätzlich muss der Caller vor jedem Funktionsaufruf immer 32 Byte sogenannten Shadow Space auf dem Stack reservieren, auch wenn alle Parameter in Registern übergeben werden.
Fehler bei der Calling Convention sind oft schwer zu debuggen. Der Code kann auf einer Architektur oder ohne Optimierungen korrekt laufen, bricht aber unter anderen Bedingungen zusammen. Mit aktivierten Optimierungen trifft der Compiler aggressive Annahmen über Registerlebenszeiten und Stacklayout. Werden diese Annahmen durch Assemblercode verletzt, entstehen Fehler, die sich nicht direkt auf eine einzelne Codezeile zurückführen lassen.
Ein weiteres wichtiges Detail ist die Stack-Ausrichtung. Auf x86-64 verlangt die System V AMD64 ABI, dass der Stack-Pointer %rsp vor jedem call-Befehl auf eine 16-Byte-Grenze ausgerichtet ist, die Adresse in %rsp muss also durch 16 teilbar sein. Da der call-Befehl eine 8 Byte große Rücksprungadresse auf den Stack legt, ist %rsp beim Eintritt in eine Funktion um 8 Byte von einer 16-Byte-Grenze entfernt. Funktionen, die weitere Funktionen aufrufen oder lokalen Speicher auf dem Stack reservieren, müssen alle Stack-Manipulationen so ausführen, dass %rsp vor jedem eigenen call wieder auf eine 16-Byte-Grenze zeigt.
Inline-Assembler muss dem Compiler alle Seiteneffekte vollständig beschreiben: Registerabhängigkeiten über Operanden und Clobbers, Speicherwirkungen über den "memory"-Clobber. Nur so bleiben Optimierungen korrekt und konsistent mit den tatsächlichen Effekten des Assemblercodes.
Debuggen von Assembler und gemischtem Code
Debugging wird komplizierter, sobald Assembler ins Spiel kommt. Debugger wie GDB können zwar Assemblercode anzeigen und schrittweise ausführen, aber die Integration mit dem C-Code ist nicht immer nahtlos.
Ein typisches Problem: Beim Steppen durch C-Code springt der Debugger plötzlich in den Assemblerblock. Die Zuordnung zwischen C-Zeilen und Assemblerinstruktionen ist nicht immer eindeutig. Der Debugger zeigt vielleicht die falsche Zeile oder überspringt Zeilen.
Ein weiteres Problem: Optimierter Code. Mit -O2 oder -O3 wird der erzeugte Assemblercode stark verändert. Variablen existieren möglicherweise nicht mehr, weil sie in Registern liegen oder wegoptimiert wurden. Der Debugger kann dann ihre Werte nicht anzeigen. Die Ausführungsreihenfolge entspricht nicht der Quellcode-Reihenfolge. Schrittweises Debuggen wird verwirrend. Bei der Fehlersuche sollte man die Optimierung ausschalten und hoffen, dass ein Bug nicht durch die Optimierung entstanden ist.
Ein weiterer Tipp: Debug-Symbole explizit einschalten (-g). Das fügt zusätzliche Informationen in die Binary ein, die dem Debugger helfen, Assemblercode auf C-Code zurückzuführen. Ohne -g sieht der Debugger nur rohe Adressen und Instruktionen.
Das Disassemblieren von Code mit eingebettetem Inline-Assembler hilft, die tatsächliche Ausführung zu verstehen. In GDB zeigt disassemble die Assemblerinstruktionen einer Funktion. layout asm und layout split zeigen Assembler und Source gleichzeitig.
Rückblick und Ausblick
In diesem Kapitel ging es nicht darum, Assembler zu lernen oder selbst Maschinenprogramme zu schreiben. Ziel war es, ein Grundverständnis dafür zu entwickeln, wie C-Code auf Maschinenebene umgesetzt wird und welche Rolle der Compiler dabei spielt. Wir haben gesehen, dass zwischen Quelltext und ausführbarem Programm mehrere klar getrennte Schritte liegen und dass der erzeugte Maschinencode oft nur noch wenig Ähnlichkeit mit der ursprünglichen C-Struktur hat. Grundlegende Assemblerkenntnisse sind dabei hilfreich, um einschätzen zu können, was der Compiler möglicherweise wegoptimiert hat und ob bestimmte Optimierungen aktiv sind oder nicht. Wer Assembler lesen kann, versteht besser, was der Compiler tatsächlich aus dem Code macht und warum Variablen oder ganze Codepfade verschwinden.
Daneben haben wir gesehen, dass es auch möglich ist, eigenen Assemblercode in C-Programme einzubetten oder extern einzubinden. Das ist kein Normalfall, kann aber in bestimmten Situationen notwendig sein, etwa bei hardwarenahen Funktionen oder sehr speziellen Performanceanforderungen. Genau hier ist besondere Vorsicht geboten. Fehler im Assembler äußern sich selten dort, wo sie entstehen. Häufig zeigen sie sich erst später als Segmentation Faults oder als schleichend korrumpierte Daten. Der Debugger meldet dann einen Absturz an einer scheinbar unverdächtigen Stelle, obwohl die eigentliche Ursache im Assembler liegt, etwa ein zerstörtes Register, ein beschädigter Stack oder eine unvollständig deklarierte Registerwirkung. Die Konsequenz ist klar: Assemblercode verlangt höchste Sorgfalt. Jede Instruktion, jedes verwendete Register und jede Stack-Operation müssen vollständig verstanden und korrekt beschrieben sein.
In der Praxis verwendet man heute normalerweise Intrinsics und nicht Inline-Assembler. Intrinsics sind vom Compiler bereitgestellte C- oder C++-Funktionen, die direkt auf einzelne Maschineninstruktionen oder klar definierte Instruktionssequenzen abgebildet werden. Der Code bleibt formal C, löst aber bewusst bestimmte CPU-Operationen aus, die in der Sprache selbst nicht ausdrückbar sind. Intrinsics gibt es für viele Bereiche. Der bekannteste ist SIMD, also Vektoroperationen wie SSE, AVX oder NEON, bei denen mehrere Datenwerte parallel verarbeitet werden. Daneben existieren Intrinsics unter anderem für atomare Operationen, Speicherbarrieren, Bitmanipulationen, Cache-Steuerung, Zeitstempelabfragen oder spezielle Steuerbefehle der CPU. In all diesen Fällen erlauben Intrinsics einen kontrollierten Zugriff auf Hardwarefunktionen, ohne selbst Assembler schreiben zu müssen.
Reiner Assemblercode kommt heute nur noch in Ausnahmefällen zum Einsatz. Dazu zählen Situationen, in denen absolute Kontrolle über die Instruktionen erforderlich ist. Ein Beispiel ist FFmpeg, das in seinen Video- und Audio-Codecs umfangreich handgeschriebenen Assembler für SIMD-Hotspots einsetzt. (Quelle: https://github.com/FFmpeg/FFmpeg/tree/master/libavcodec/x86) Dort ist der Aufwand gerechtfertigt, weil kleinste Effizienzgewinne messbare Auswirkungen haben. Für normalen Anwendungs- und Systemcode ist dieser Ansatz jedoch die Ausnahme, nicht die Regel.
Was Assembler in diesem Kapitel für C war, übernimmt C im nächsten Kapitel für höhere Programmiersprachen. So wie wir Assembler herangezogen haben, um zu verstehen, was der Compiler tatsächlich aus C-Code macht, dient C in vielen Systemen als verbindende Basisebene für Sprachen wie Python oder Java. Diese Sprachen implementieren Laufzeitumgebungen in C, binden C-Bibliotheken ein oder nutzen klar definierte C-Schnittstellen, um mit nativen Komponenten zu kommunizieren. Im nächsten Kapitel wechseln wir daher die Perspektive: C steht nicht mehr nur als eigene Programmiersprache im Fokus, sondern als Integrationssprache.